This is part 6 in my series on writing modern idiomatic pandas.
Visualization and Exploratory Analysis
A few weeks ago, the R community went through some hand-wringing about plotting packages. For outsiders (like me) the details aren’t that important, but some brief background might be useful so we can transfer the takeaways to Python. The competing systems are “base R”, which is the plotting system built into the language, and ggplot2, Hadley Wickham’s implementation of the grammar of graphics. For those interested in more details, start with
The most important takeaways are that
- Either system is capable of producing anything the other can
- ggplot2 is usually better for exploratory analysis
Item 2 is not universally agreed upon, and it certainly isn’t true for every type of chart, but we’ll take it as fact for now. I’m not foolish enough to attempt a formal analogy here, like “matplotlib is python’s base R”. But there’s at least a rough comparison: like dplyr/tidyr and ggplot2, the combination of pandas and seaborn allows for fast iteration and exploration. When you need to, you can “drop down” into matplotlib for further refinement.
Overview
Here’s a brief sketch of the plotting landscape as of April 2016. For some reason, plotting tools feel a bit more personal than other parts of this series so far, so I feel the need to blanket this who discussion in a caveat: this is my personal take, shaped by my personal background and tastes. Also, I’m not at all an expert on visualization, just a consumer. For real advice, you should listen to the experts in this area. Take this all with an extra grain or two of salt.
Matplotlib
Matplotlib is an amazing project, and is the foundation of pandas’ built-in plotting and Seaborn. It handles everything from the integration with various drawing backends, to several APIs handling drawing charts or adding and transforming individual glyphs (artists). I’ve found knowing the pyplot API useful. You’re less likely to need things like Transforms or artists, but when you do the documentation is there.
Matplotlib has built up something of a bad reputation for being verbose. I think that complaint is valid, but misplaced. Matplotlib lets you control essentially anything on the figure. An overly-verbose API just means there’s an opportunity for a higher-level, domain specific, package to exist (like seaborn for statistical graphics).
Pandas’ builtin-plotting
DataFrame and Series have a .plot namespace, with various chart types available (line, hist, scatter, etc.).
Pandas objects provide additional metadata that can be used to enhance plots (the Index for a better automatic x-axis then range(n) or Index names as axis labels for example).
And since pandas had fewer backwards-compatibility constraints, it had a bit better default aesthetics. The matplotlib 2.0 release will level this, and pandas has deprecated its custom plotting styles, in favor of matplotlib’s (technically I just broke it when fixing matplotlib 1.5 compatibility, so we deprecated it after the fact).
At this point, I see pandas DataFrame.plot as a useful exploratory tool for quick throwaway plots.
Seaborn
Seaborn, created by Michael Waskom, “provides a high-level interface for drawing attractive statistical graphics.” Seaborn gives a great API for quickly exploring different visual representations of your data. We’ll be focusing on that today
Bokeh
Bokeh is a (still under heavy development) visualiztion library that targets the browser.
Like matplotlib, Bokeh has a few APIs at various levels of abstraction. They have a glyph API, which I suppose is most similar to matplotlib’s Artists API, for drawing single or arrays of glpyhs (circles, rectangles, polygons, etc.). More recently they introduced a Charts API, for producing canned charts from data structures like dicts or DataFrames.
Other Libraries
This is a (probably incomplete) list of other visualization libraries that I don’t know enough about to comment on
It’s also possible to use Javascript tools like D3 directly in the Jupyter notebook, but we won’t go into those today.
Examples
I do want to pause and explain the type of work I’m doing with these packages. The vast majority of plots I create are for exploratory analysis, helping me understand the dataset I’m working with. They aren’t intended for the client (whoever that is) to see. Occasionally that exploratory plot will evolve towards a final product that will be used to explain things to the client. In this case I’ll either polish the exploratory plot, or rewrite it in another system more suitable for the final product (in D3 or Bokeh, say, if it needs to be an interactive document in the browser).
Now that we have a feel for the overall landscape (from my point of view), let’s delve into a few examples.
We’ll use the diamonds dataset from ggplot2.
You could use Vincent Arelbundock’s RDatasets package to find it (pd.read_csv('http://vincentarelbundock.github.io/Rdatasets/csv/ggplot2/diamonds.csv')), but I wanted to checkout feather.
import os
import feather
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
if int(os.environ.get("MODERN_PANDAS_EPUB", 0)):
import prep # noqa
%load_ext rpy2.ipython
%%R
suppressPackageStartupMessages(library(ggplot2))
library(feather)
write_feather(diamonds, 'diamonds.fthr')
import feather
df = feather.read_dataframe('diamonds.fthr')
df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 53940 entries, 0 to 53939
Data columns (total 10 columns):
carat 53940 non-null float64
cut 53940 non-null category
color 53940 non-null category
clarity 53940 non-null category
depth 53940 non-null float64
table 53940 non-null float64
price 53940 non-null int32
x 53940 non-null float64
y 53940 non-null float64
z 53940 non-null float64
dtypes: category(3), float64(6), int32(1)
memory usage: 2.8 MB
It’s not clear to me where the scientific community will come down on Bokeh for exploratory analysis. The ability to share interactive graphics is compelling. The trend towards more and more analysis and communication happening in the browser will only enhance this feature of Bokeh.
Personally though, I have a lot of inertia behind matplotlib so I haven’t switched to Bokeh for day-to-day exploratory analysis.
I have greatly enjoyed Bokeh for building dashboards and webapps with Bokeh server. It’s still young, and I’ve hit some rough edges, but I’m happy to put up with some awkwardness to avoid writing more javascript.
sns.set(context='talk', style='ticks')
%matplotlib inline
Matplotlib
Since it’s relatively new, I should point out that matplotlib 1.5 added support for plotting labeled data.
fig, ax = plt.subplots()
ax.scatter(x='carat', y='depth', data=df, c='k', alpha=.15);
This isn’t limited to just DataFrames.
It supports anything that uses __getitem__ (square-brackets) with string keys.
Other than that, I don’t have much to add to the matplotlib documentation.
Pandas Built-in Plotting
The metadata in DataFrames gives a bit better defaults on plots.
df.plot.scatter(x='carat', y='depth', c='k', alpha=.15)
plt.tight_layout()
We get axis labels from the column names. Nothing major, just nice.
Pandas can be more convenient for plotting a bunch of columns with a shared x-axis (the index), say several timeseries.
from pandas_datareader import fred
gdp = fred.FredReader(['GCEC96', 'GPDIC96'], start='2000-01-01').read()
gdp.rename(columns={"GCEC96": "Government Expenditure",
"GPDIC96": "Private Investment"}).plot(figsize=(12, 6))
plt.tight_layout()
/Users/taugspurger/miniconda3/envs/modern-pandas/lib/python3.6/site-packages/ipykernel_launcher.py:3: DeprecationWarning: pandas.core.common.is_list_like is deprecated. import from the public API: pandas.api.types.is_list_like instead
This is separate from the ipykernel package so we can avoid doing imports until
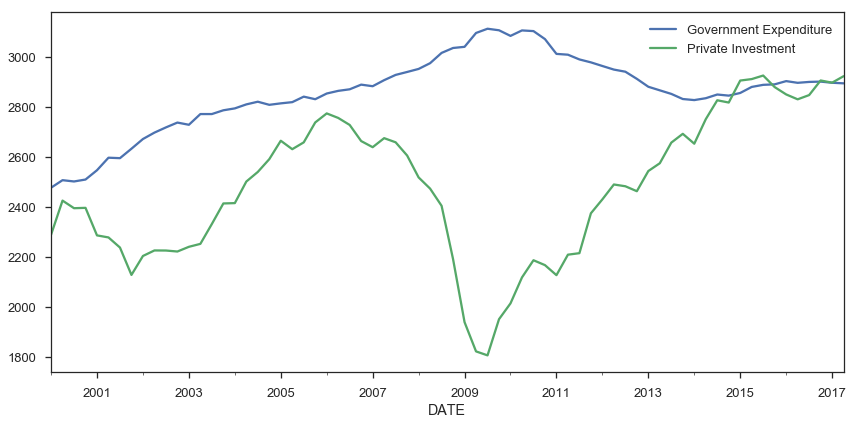
Seaborn
The rest of this post will focus on seaborn, and why I think it’s especially great for exploratory analysis.
I would encourage you to read Seaborn’s introductory notes, which describe its design philosophy and attempted goals. Some highlights:
Seaborn aims to make visualization a central part of exploring and understanding data.
It does this through a consistent, understandable (to me anyway) API.
The plotting functions try to do something useful when called with a minimal set of arguments, and they expose a number of customizable options through additional parameters.
Which works great for exploratory analysis, with the option to turn that into something more polished if it looks promising.
Some of the functions plot directly into a matplotlib axes object, while others operate on an entire figure and produce plots with several panels.
The fact that seaborn is built on matplotlib means that if you are familiar with the pyplot API, your knowledge will still be useful.
Most seaborn plotting functions (one per chart-type) take an x, y, hue, and data arguments (only some are required, depending on the plot type). If you’re working with DataFrames, you’ll pass in strings referring to column names, and the DataFrame for data.
sns.countplot(x='cut', data=df)
sns.despine()
plt.tight_layout()
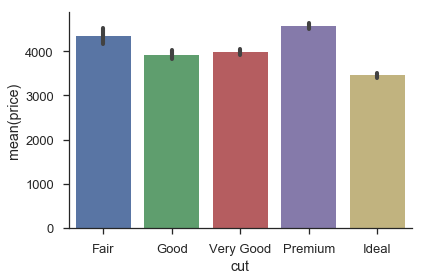
sns.barplot(x='cut', y='price', data=df)
sns.despine()
plt.tight_layout()
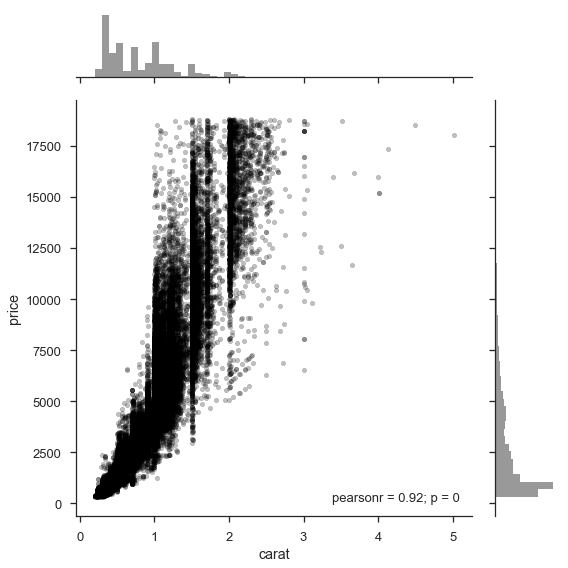
Bivariate relationships can easily be explored, either one at a time:
sns.jointplot(x='carat', y='price', data=df, size=8, alpha=.25,
color='k', marker='.')
plt.tight_layout()
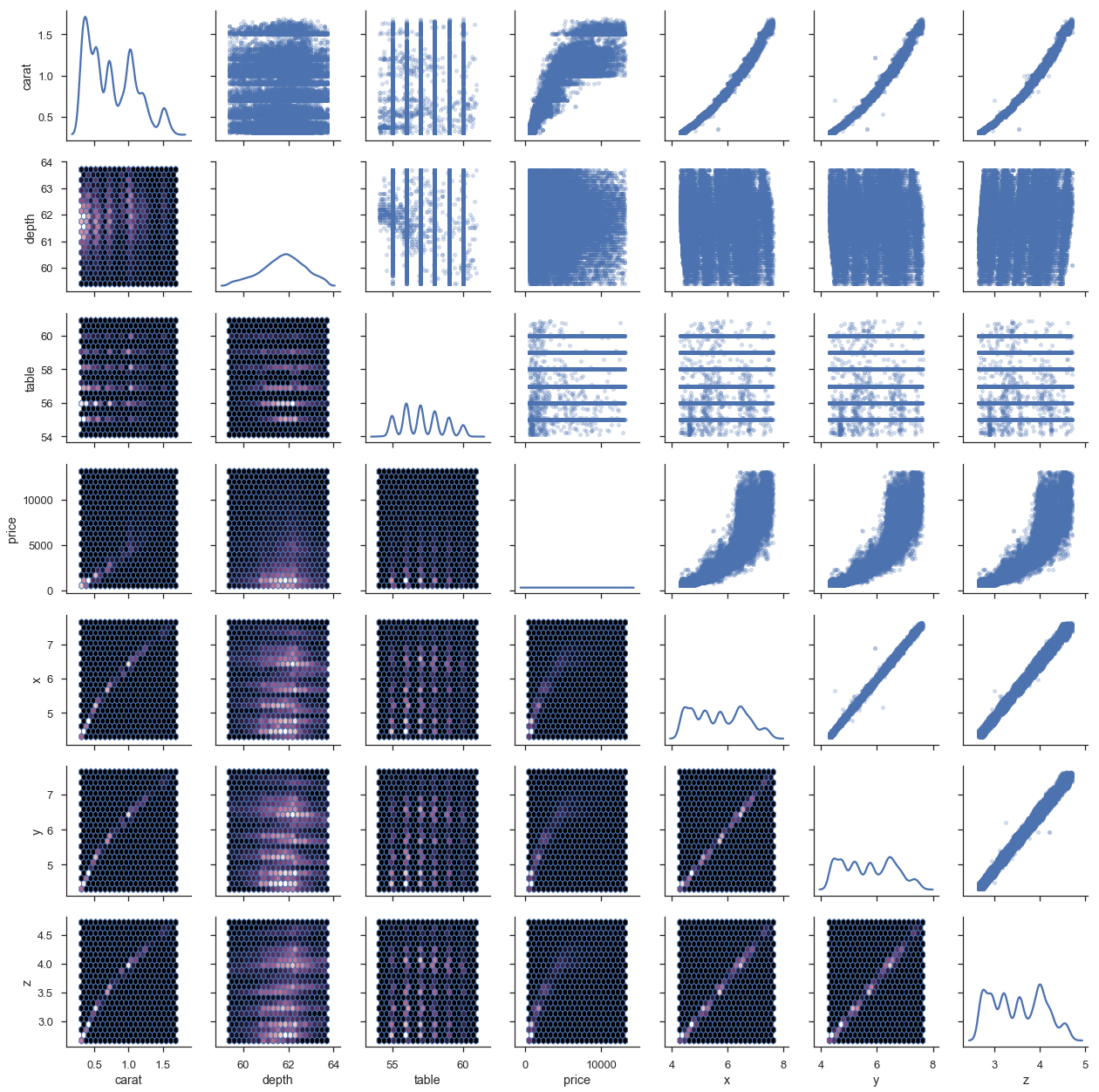
Or many at once
g = sns.pairplot(df, hue='cut')

pairplot is a convenience wrapper around PairGrid, and offers our first look at an important seaborn abstraction, the Grid. Seaborn Grids provide a link between a matplotlib Figure with multiple axes and features in your dataset.
There are two main ways of interacting with grids. First, seaborn provides convenience-wrapper functions like pairplot, that have good defaults for common tasks. If you need more flexibility, you can work with the Grid directly by mapping plotting functions over each axes.
def core(df, α=.05):
mask = (df > df.quantile(α)).all(1) & (df < df.quantile(1 - α)).all(1)
return df[mask]
cmap = sns.cubehelix_palette(as_cmap=True, dark=0, light=1, reverse=True)
(df.select_dtypes(include=[np.number])
.pipe(core)
.pipe(sns.PairGrid)
.map_upper(plt.scatter, marker='.', alpha=.25)
.map_diag(sns.kdeplot)
.map_lower(plt.hexbin, cmap=cmap, gridsize=20)
);
This last example shows the tight integration with matplotlib. g.axes is an array of matplotlib.Axes and g.fig is a matplotlib.Figure.
This is a pretty common pattern when using seaborn: use a seaborn plotting method (or grid) to get a good start, and then adjust with matplotlib as needed.
I think (not an expert on this at all) that one thing people like about the grammar of graphics is its flexibility.
You aren’t limited to a fixed set of chart types defined by the library author.
Instead, you construct your chart by layering scales, aesthetics and geometries.
And using ggplot2 in R is a delight.
That said, I wouldn’t really call what seaborn / matplotlib offer that limited. You can create pretty complex charts suited to your needs.
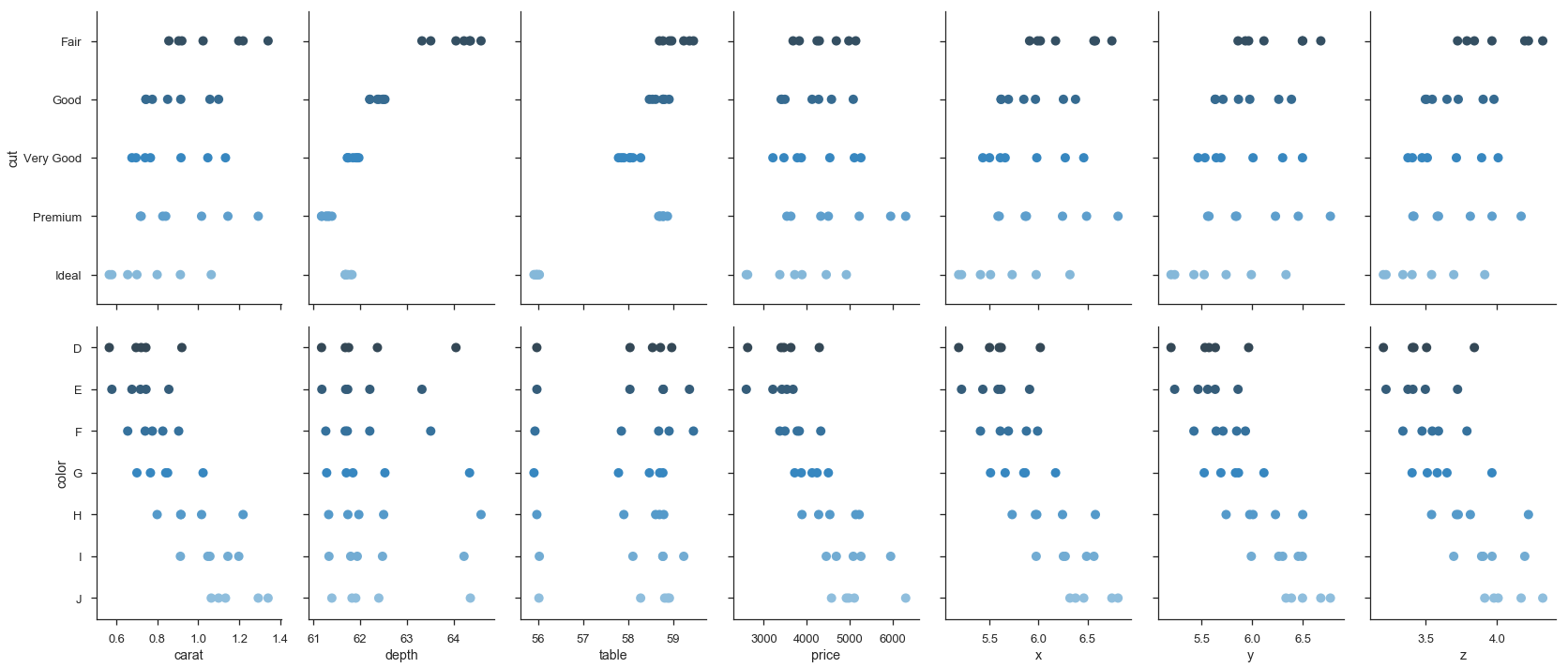
agged = df.groupby(['cut', 'color']).mean().sort_index().reset_index()
g = sns.PairGrid(agged, x_vars=agged.columns[2:], y_vars=['cut', 'color'],
size=5, aspect=.65)
g.map(sns.stripplot, orient="h", size=10, palette='Blues_d');
g = sns.FacetGrid(df, col='color', hue='color', col_wrap=4)
g.map(sns.regplot, 'carat', 'price');
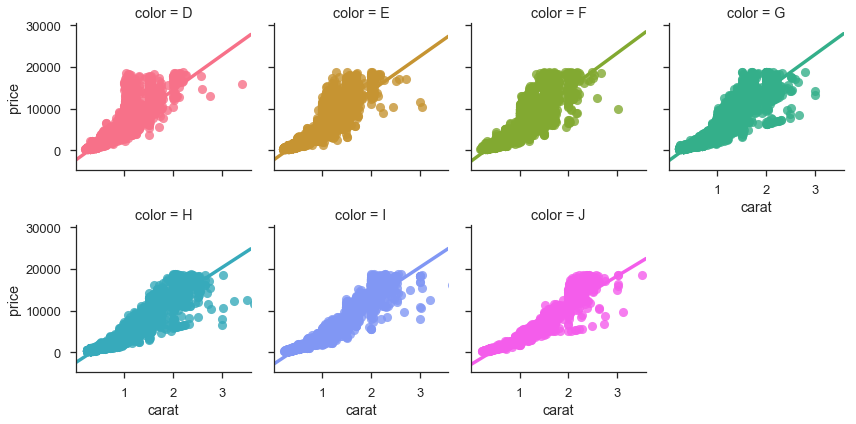
Initially I had many more examples showing off seaborn, but I’ll spare you. Seaborn’s documentation is thorough (and just beautiful to look at).
We’ll end with a nice scikit-learn integration for exploring the parameter-space on a GridSearch object.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
For those unfamiliar with machine learning or scikit-learn, the basic idea is your algorithm (RandomForestClassifer) is trying to maximize some objective function (percent of correctly classified items in this case).
There are various hyperparameters that affect the fit.
We can search this space by trying out a bunch of possible values for each parameter with the GridSearchCV estimator.
df = sns.load_dataset('titanic')
clf = RandomForestClassifier()
param_grid = dict(max_depth=[1, 2, 5, 10, 20, 30, 40],
min_samples_split=[2, 5, 10],
min_samples_leaf=[2, 3, 5])
est = GridSearchCV(clf, param_grid=param_grid, n_jobs=4)
y = df['survived']
X = df.drop(['survived', 'who', 'alive'], axis=1)
X = pd.get_dummies(X, drop_first=True)
X = X.fillna(value=X.median())
est.fit(X, y);
scores = pd.DataFrame(est.cv_results_)
scores.head()
| mean_fit_time | mean_score_time | mean_test_score | mean_train_score | param_max_depth | param_min_samples_leaf | param_min_samples_split | params | rank_test_score | split0_test_score | split0_train_score | split1_test_score | split1_train_score | split2_test_score | split2_train_score | std_fit_time | std_score_time | std_test_score | std_train_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.017463 | 0.002174 | 0.786756 | 0.797419 | 1 | 2 | 2 | {'max_depth': 1, 'min_samples_leaf': 2, 'min_s... | 54 | 0.767677 | 0.804714 | 0.808081 | 0.797980 | 0.784512 | 0.789562 | 0.000489 | 0.000192 | 0.016571 | 0.006198 |
| 1 | 0.014982 | 0.001843 | 0.773288 | 0.783951 | 1 | 2 | 5 | {'max_depth': 1, 'min_samples_leaf': 2, 'min_s... | 57 | 0.767677 | 0.804714 | 0.754209 | 0.752525 | 0.797980 | 0.794613 | 0.001900 | 0.000356 | 0.018305 | 0.022600 |
| 2 | 0.013890 | 0.001895 | 0.771044 | 0.786195 | 1 | 2 | 10 | {'max_depth': 1, 'min_samples_leaf': 2, 'min_s... | 58 | 0.767677 | 0.811448 | 0.754209 | 0.752525 | 0.791246 | 0.794613 | 0.000935 | 0.000112 | 0.015307 | 0.024780 |
| 3 | 0.015679 | 0.001691 | 0.764310 | 0.760943 | 1 | 3 | 2 | {'max_depth': 1, 'min_samples_leaf': 3, 'min_s... | 61 | 0.801347 | 0.799663 | 0.700337 | 0.695286 | 0.791246 | 0.787879 | 0.001655 | 0.000025 | 0.045423 | 0.046675 |
| 4 | 0.013034 | 0.001695 | 0.765432 | 0.787318 | 1 | 3 | 5 | {'max_depth': 1, 'min_samples_leaf': 3, 'min_s... | 60 | 0.710438 | 0.772727 | 0.801347 | 0.781145 | 0.784512 | 0.808081 | 0.000289 | 0.000038 | 0.039490 | 0.015079 |
sns.factorplot(x='param_max_depth', y='mean_test_score',
col='param_min_samples_split',
hue='param_min_samples_leaf',
data=scores);
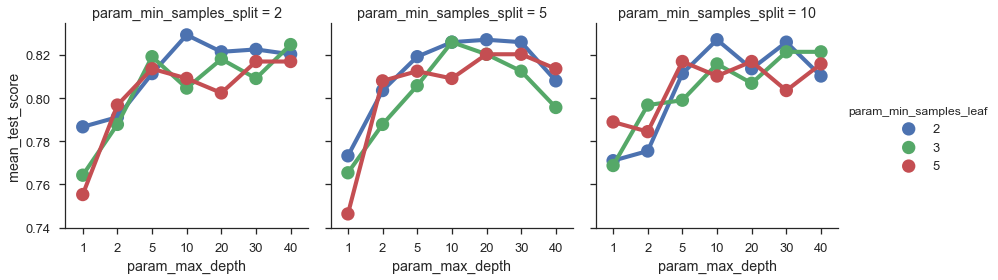
Thanks for reading! I want to reiterate at the end that this is just my way of doing data visualization. Your needs might differ, meaning you might need different tools. You can still use pandas to get it to the point where it’s ready to be visualized!
As always, feedback is welcome.